Intel Updates ISA Manual: New Instructions for Alder Lake, also BF16 for Sapphire Rapids
by Dr. Ian Cutress on April 1, 2020 5:00 AM EST- Posted in
- CPUs
- Intel
- TSX
- Security
- Sapphire Rapids
- Alder Lake
- Instructions

As with any processor vendor, having a detailed list of what the processor does and how to optimize for it is important. Helping programmers also plan for what’s coming is also vital. To that end, we often get glimpses of what is coming in future products by keeping track of these updates. Not only does it give detail on the new instructions, but it often verifies code names for products that haven’t ‘officially’ been recognized. Intel’s latest update to its ISA Extensions Reference manual does just this, confirming Alder Lake as a future product, and identifies what new instructions are coming in future platforms. Perhaps the biggest news of this is actually the continuation of BFLOAT16 support, originally supposed to be Cooper Lake only (and bearing in mind, Cooper Lake will have a limited launch), but will now also be included in the upcoming Sapphire Rapids generation, set for deployment in the Aurora supercomputer in late 2021.
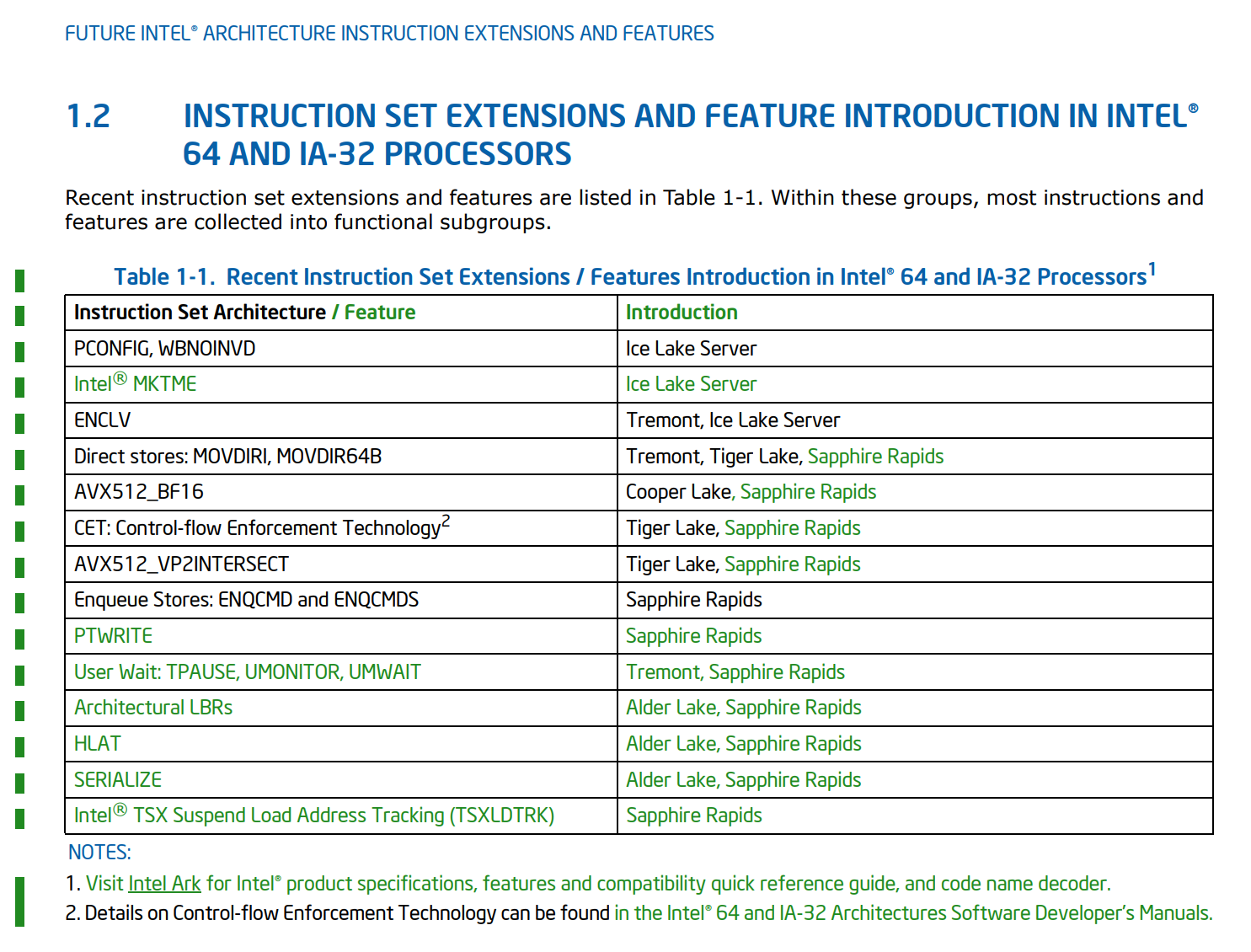
In the 38th Edition of the ISA Extensions Reference manual from Intel, the company has a table front and center with all the latest updates an instructions coming to future platforms. From this, we can plot what platforms will be getting which instructions.
| Intel Instruction Support | ||||||
| AnandTech | Tremont Atom |
CPR Xeon |
ICL Xeon |
SPR Xeon |
Tiger Lake |
Alder Lake |
| PCONFIG | ✓ | ? | ||||
| WBNOINVD | ✓ | ? | ||||
| Intel MKTME | ✓ | ? | ||||
| ENCLV | ✓ | ✓ | ? | |||
| MOVDIR* | ✓ | ✓ | ✓ | ? | ||
| AVX512_BF16 | ✓ | no | ✓ | |||
| AVX512_VP2INTERSECT | ✓ | ✓ | ? | |||
| CET | ✓ | ✓ | ? | |||
| ENQCMD* | ✓ | |||||
| PTWRITE | ✓ | |||||
| TPAUSE, UM* | ✓ | ✓ | ||||
| Arch LBRs | ✓ | ✓ | ||||
| HLAT | ✓ | ✓ | ||||
| SERIALIZE | ✓ | ✓ | ||||
| TSXLDTRK | ✓ | |||||
Starting with what I think is big news: BF16 support in Sapphire Rapids. It is clear from this manual that BF16 will not be supported in Ice Lake Server, which means that technically BF16 will skip a generation, going from Cooper Lake to Sapphire Rapids. But as we’ve reported on previously, Cooper Lake has changed from a wide launch for everyone to a minimal launch for select customers only, and those that focus on 4S and 8S topologies (like Facebook). So this could be considered more of a ‘delayed’ launch, assuming Sapphire Rapids is going to be widely used. Anyone planning to use Cooper Lake for BF16 compatible workloads will have to wait an extra couple of years.
The other big news is the mentioning of Alder Lake. Up until this point, Alder Lake has only been mentioned in unconfirmed slides, or LinkedIn profiles of engineers who have worked on it (and subsequently those references were removed). As far as we understand, Alder Lake is the 10nm product following on from Tiger Lake. Tiger Lake (what we know so far) is a quad-core mobile chip due for launch at the end of 2020, which means Alder Lake is likely to be at the tail end of 2021.
What Alder Lake (and Sapphire Rapids) gets for instructions includes Architectural LBRs (Last Branch Recording) in order to speed up branches, HLAT (Hypervisor-managed Linear Address Translation), which forces linear address translation, and SERIALIZE, which forces a command to go through a core with all the caches pre-flushed and waits for all buffered writes to have finished before starting. The LBR update helps with performance, the HLAT is primarily for Sapphire Rapids, and the SERIALIZE is to assist with recent security issues.
Also of note are some of the Ice Lake Server updates. It now lists Ice Lake Server as getting Intel’s MKTME, Intel’s Multi-Key Total Memory Encryption, which are a set of memory encryption techniques for multiple encrypted environments, increasing the scope of these technologies with a key to matching/surpassing AMD’s prowess in this area. The other one to note (but not new for this document) is ENCLV support, which SGX related to secure enclaves.
Another point of security is the new TSXLDTRK instruction for Sapphire Rapids. This is a TSX Load Tracking ‘suspend’ instruction, with a corresponding XRESLDTRK to resume load tracking for TSX. (TSX = Transactional Memory.)
The full information about these new instructions can be found on Intel’s Developer Zone.
Source: Instlatx64 on Twitter
Related Reading
- I Ran Off with Intel’s Tiger Lake Wafer. Who Wants a Die Shot?
- Intel’s Cooper Lake Plans: The Chip That Wasn’t Meant to Exist, Fades Away
- Intel to Offer Socketed 56-core Cooper Lake Xeon Scalable in new Socket Compatible with Ice Lake
- Intel Architecture Manual Updates: bfloat16 for Cooper Lake Xeon Scalable Only?
- Cisco Documents Shed Light on Cascade Lake, Cooper Lake, and Ice Lake for Servers
- An Interview with Lisa Spelman, VP of Intel’s DCG: Discussing Cooper Lake and Smeltdown
- Intel at CES 2020: 45W 10th Gen Mobile CPUs Soon, Tiger Lake with Xe Graphics Later
- Intel’s Confusing Messaging: Is Comet Lake Better Than Ice Lake?








34 Comments
View All Comments
JayNor - Thursday, April 2, 2020 - link
Intel's Agilex FPGAs also support bfloat16, according to this:https://www.intel.com/content/dam/www/programmable...
"hard fixed-point and IEEE 754 compliant hard floating-point variable precisiondigital signal processing (DSP) blocks providing up to 40 TFLOPS of FP16 orBFLOAT16 compute performance"
JayNor - Thursday, April 2, 2020 - link
The main advantage of bfloat16 is that it has been demonstrated to substitute well for fp32 in training. In Intel's case Cooper Lake avx512 should be able to double the fp32 equivalent training operations per cycle.https://arxiv.org/abs/1905.12322
"Our results show that deep learning training using BFLOAT16 tensors achieves the same state-of-the-art (SOTA) results across domains as FP32 tensors in the same number of iterations and with no changes to hyper-parameters. "
abufrejoval - Monday, April 6, 2020 - link
Never read beyond April 1st...Yet I wonder, why I didn't see it pop up before? Did it get delayed in some pipeline?
Where is the Renoir vs. iCan'tCompeteAny14ore comparison promised for today?
JayNor - Sunday, April 12, 2020 - link
MSFT uses ms-fp8 in their Brainwave project, which is about 3x faster than int8 on an intel stratix 10 or aria 10 fpga.