AMD's Graphics Core Next Preview: AMD's New GPU, Architected For Compute
by Ryan Smith on December 21, 2011 9:38 PM ESTMany SIMDs Make One Compute Unit
When we move up a level we have the Compute Unit, what AMD considers the fundamental unit of computation. Whereas a single SIMD can execute vector operations and that’s it, combined with a number of other functional units it makes a complete unit capable of the entire range of compute tasks. In practice this replaces a Cayman SIMD, which was a collection of Cayman SPs. However a GCN Compute Unit is capable of far, far more than a Cayman SIMD.
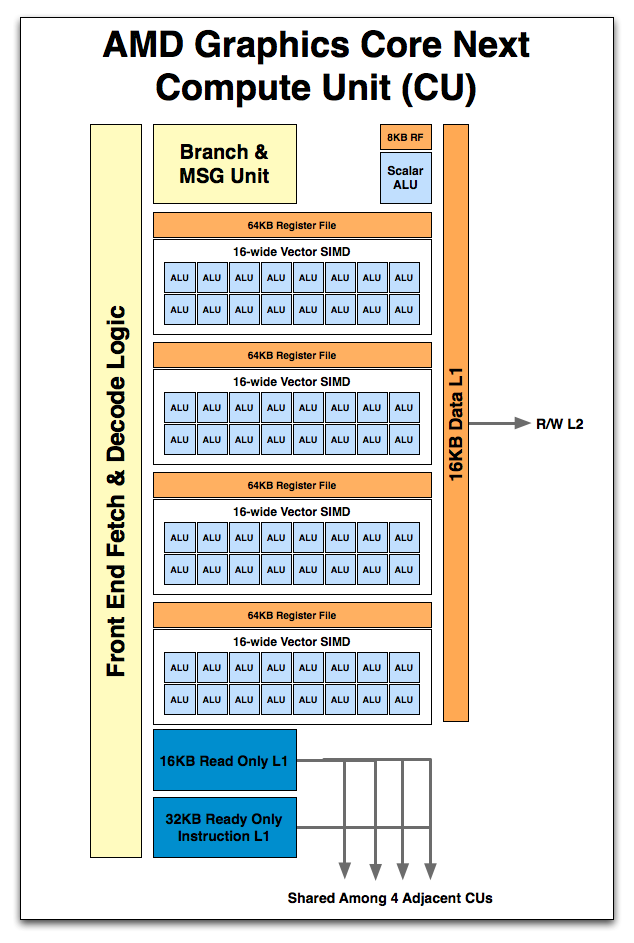
So what’s in a Compute Unit? Just as a Cayman SIMD was a collection of SPs, a Compute Unit starts with a collection of SIMDs. 4 SIMDs are in a CU, meaning that like a Cayman SIMD, a GCN CU can work on 4 instructions at once. Also in a Compute Unit is the control hardware & branch unit responsible for fetching, decoding, and scheduling wavefronts and their instructions. This is further augmented with a 64KB Local Data Store and 16KB of L1 data + texture cache. With GCN data and texture L1 are now one and the same, and texture pressure on the L1 cache has been reduced by the fact that AMD is now keeping compressed rather than uncompressed texels in the L1 cache. Rounding out the memory subsystem is access to the L2 cache and beyond. Finally there is a new unit: the scalar unit. We’ll get back to that in a bit.
But before we go any further, let’s stop here for a moment. Now that we know what a CU looks like and what the weaknesses are of VLIW, we can finally get to the meat of the issue: why AMD is dropping VLIW for non-VLIW SIMD. As we mentioned previously, the weakness of VLIW is that it’s statically scheduled ahead of time by the compiler. As a result if any dependencies crop up while code is being executed, there is no deviation from the schedule and VLIW slots go unused. So the first change is immediate: in a non-VLIW SIMD design, scheduling is moved from the compiler to the hardware. It is the CU that is now scheduling execution within its domain.
Now there’s a distinct tradeoff with dynamic hardware scheduling: it can cover up dependencies and other types of stalls, but that hardware scheduler takes up die space. The reason that the R300 and earlier GPUs were VLIW was because the compiler could do a fine job for graphics, and the die space was better utilized by filling it with additional functional units. By moving scheduling into hardware it’s more dynamic, but we’re now consuming space previously used for functional units. It’s a tradeoff.
So what can you do with dynamic scheduling and independent SIMDs that you could not do with Cayman’s collection of SPs (SIMDs)? You can work around dependencies and schedule around things. The worst case scenario for VLIW is that something scheduled is completely dependent or otherwise blocking the instruction before and after it – it must be run on its own. Now GCN is not an out-of-order architecture; within a wavefront the instructions must still be executed in order, so you can’t jump through a pixel shader program for example and execute different parts of it at once. However the CU and SIMDs can select a different wavefront to work on; this can be another wavefront spawned by the same task (e.g. a different group of pixels/values) or it can be a wavefront from a different task entirely.
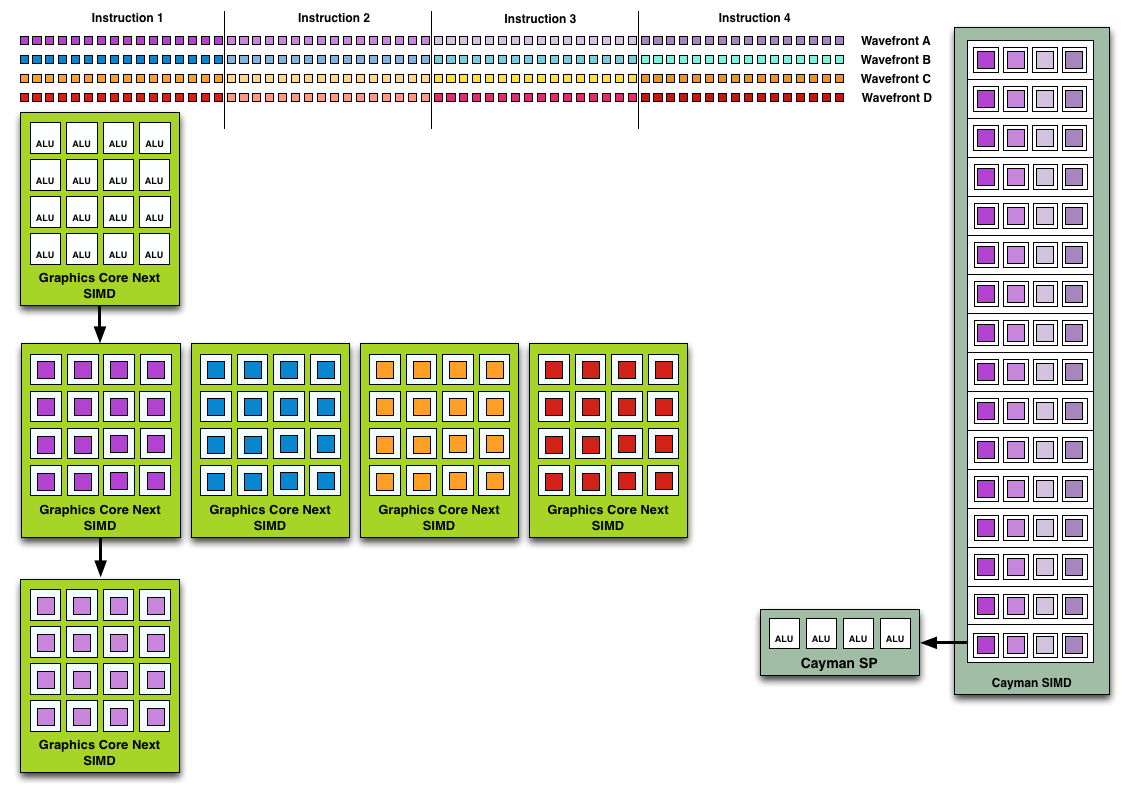
Wavefront Execution Example: SIMD vs. VLIW. Not To Scale - Wavefront Size 16
Cayman had a very limited ability to work on multiple tasks at once. While it could consume multiple wavefronts from the same task with relative ease, its ability to execute concurrent tasks was reliant on the API support, which was limited to an extension to OpenCL. With these hardware changes, GCN can now concurrently work on tasks with relative ease. Each GCN SIMD has 10 wavefronts to choose from, meaning each CU in turn has up to a total of 40 wavefronts in flight. This in a nutshell is why AMD is moving from VLIW to non-VLIW SIMD for Graphics Core Next: instead of VLIW slots going unused due to dependencies, independent SIMDs can be given entirely different wavefronts to work on.
As a consequence, compiling also becomes much easier. With the compiler freed from scheduling tasks, compilation behaves in a rather standard manner, since most other architectures are similarly scheduled in hardware. Writing a compiler still isn’t absolutely easy, but when it comes to optimizing the execution of a program the compiler can focus on other matters, making it much easier for other languages to target GCN. In fact without the need to generate long VLIW instructions or to including scheduling information, the underlying ISA for GCN is also much simpler. This makes debugging much easier since the code generated reflects the fact that scheduling is now done in hardware, which is reflected in our earlier assembly code example.
Now while leaving behind the drawbacks of VLIW is the biggest architectural improvement for compute performance coming from Cayman, the move to non-VLIW SIMDs is not the only benefit. We still have not discussed the final component of the CU: the Scalar ALU. New to GCN, the Scalar unit serves to further keep inefficient operations out of the SIMDs, leaving the vector ALUs on the SIMDs to execute instructions en mass. The scalar unit is composed of a single scalar ALU, along with an 8KB register file.
So what does a scalar unit do? First and foremost it executes “one-off” mathematical operations. Whole groups of pixels/values go through the vector units together, but independent operations go to the scalar unit as to not waste valuable SIMD time. This includes everything from simple integer operations to control flow operations like conditional branches (if/else) and jumps, and in certain cases read-only memory operations from a dedicated scalar L1 cache. Overall the scalar unit can execute one instruction per cycle, which means it can complete 4 instructions over the period of time it takes for one wavefront to be completed on a SIMD.
Conceptually this blurs a bit more of the remaining line between a scalar GPU and a vector GPU, but by having both types of units it means that each unit type can work on the operations best suited for it. Besides avoiding feeding SIMDs non-vectorized datasets, this will also improve the latency for control flow operations, where Cayman had a rather nasty 44 cycle latency.








83 Comments
View All Comments
Targon - Sunday, June 19, 2011 - link
AMD wants to put an end to the GPU in the chipset, but no one expects dedicated CPU and GPU to go away. Now, the code that would take advantage of the APU would probably work with a full AMD CPU/AMD GPU combination, so the software side of things would not need a lot of change to support both configurations.khimera2000 - Sunday, June 19, 2011 - link
Agree, dedicated cards will not go away, however intergrated cards like the past will.I think we see Eye to Eye on this. AMD wants to take full advantage of all its hardware, It looks like the way there trying to do it is by combining the CPU and Intergrated GPU into one package, after which they want to set it up so infromation that goes into that package dosent have to leave to be processed, like sending it out to ram from the CPU only to be read by the GPU.
Still want to see how this will work across PCI-E. I can already see future reviews and comparisons on how effetive GPU acceleration is on there intergrated aproach VS discreet cards. AND Buying those discreet cards :D
By the time these parts comes out my desktop will be right in the middle of its upgrade cycle :D
Targon - Monday, June 20, 2011 - link
AMD needs to push for the HTX slot again for discrete video, where there is a direct HyperTransport link between the CPU and whatever is plugged into that slot. PCI-Express is decent, but HTX would and should blow the doors off PCI-Express.rnssr71 - Friday, June 17, 2011 - link
i wish this coming next year especially in Trinity but at lest they are heading in the right direction:) also, to those wondering about improvements in gaming ability, look what amd did with cayman vs cypress- the improved efficiency and noticeably improved performance on the same manufacturing. http://www.anandtech.com/bench/Product/294?vs=331GCN this is going to improve efficiency even farther and they are cutting the transistor size roughly in half.
nlr_2000 - Saturday, June 18, 2011 - link
"Unfortunately, those of you expecting any additional graphics information will have to sight tight for the time being." sight = sitEnerJi - Saturday, June 18, 2011 - link
I wonder if this architecture would be a particularly good fit for a next-generation Xbox (due around 2013)? Any thoughts on this?GaMEChld - Saturday, June 18, 2011 - link
2013? I heard 2015, unless they recently changed dates to counter Nintendo. Anyways, I'm not so sure what benefits a console will realize from this, since full blown PC's barely get to utilize much of the technology we currently have access to. Multi-threading, 64-bit support, advanced cpu instructions are all available yet barely utilized features.Also, consoles are designed to be cost effective and relatively cheap, so usually modified older generation architecture is used. For example, the new Wii uses Radeon 4700 class graphics, which sounds old but is roughly twice as powerful as the X360 (Radeon X1900) or PS3 (GF7000) graphics.
DanNeely - Saturday, June 18, 2011 - link
That's true of the Wii because Nintendo doesn't subsidize the console, but MS and Sony have gone after higher end GPUs for their last launches. The XBox 360 launched using a GPU similar to that of the ATI 1900, a bare month and a half after the card hit the market.The PS3 used a GF7800 derivative and launched roughly 1 year after the GF7800 did. The GF7900 was nVidias top of the line card at the time, but it was only a marginal improvement over the 7800.swaaye - Saturday, June 18, 2011 - link
PS3 actually launched about when G80 came out, which obviously made RSX look awfully retro when you saw 7900GTX SLI being beaten in reviews by a single board. ;) But G80 surely was never an option for a console due to size and power.Xenos has less than half of the pixel fillrate of X1900. X1900 also has 48 pixel shader units + 8 vertex shaders so it might have an advantage over Xenos 48 unified units, especially when clock speed and the access to a large RAM pool over a 256-bit bus are taken into account.
GaMEChld - Sunday, June 19, 2011 - link
But we must also bear in mind that X360 and PS3 may have chosen high on the scale because of the concurrent shift to 720p/1080p resolution instead of the old 480p standard. At this point in time, the 1080p resolution is standardized, so greatly escalating GPU horsepower will show diminishing gains, since people aren't really going to be gaming on higher resolutions than the new standard tv resolution.What I mean is, if a Radeon 5000 Series could maximize all graphics quality at 1080p, why would a console manufacturer bother with more power?
For example, you wouldn't buy a GTX590 or Radeon 6990 just to game on a 1080p monitor, would you?
The only exception I can think of for this TV resolution argument is 3DTV gaming, in which case I am not well versed in the added GPU overhead required to render a 3D game.